

Tracery is a grammar construction tool widely used in making complex sentences, and it serves as a major text generation tool for Twitter bots. In this post, we’ll cover:
- what a context-free grammar is,
- how to use Tracery as a context-free grammar,
- show a tool for making Twitter bots with Tracery widely used by Twitter bot makers like Nora Reed,
- as well as show some tools that make writing and testing Tracery code a bit easier.
This is gonna be a lot of stuff to take in, so strap in and get ready to learn.
Context-Free Grammar
The basis of context-free grammars is what’s called an alphabet. An alphabet is simply a set of statements or symbols that bear meaning within the grammar. These statements or symbols fall into two categories: terminal and non-terminal. These categorizations refer to whether or not the symbol has production rules. These are often just called rules, especially in Tracery. But the idea of production rules is that non-terminal symbols are replaced with other symbols, which can either be terminal or non-terminal. Terminal symbols do not have production rules and therefore serve as a means of ending the sets of expansions. Expansions are what occurs within our production rules; they are the replacement of non-terminal symbols. So, now that we’ve defined all these terms, let’s see them in action.
We’ll start with a small set of symbols separated by commas, half of which are terminal and half of which are non-terminal.
Non-Terminal: A, B, C Terminal: D, E, F
These symbols make up our previously defined alphabet. Now we want to set up our production rules. I’ll use an arrow (–>) to show what the expansions of each non-terminal symbol are.
A --> EBF B --> EC C --> D
I want to note that so far all of these determinations have been made arbitrarily, but when implementing into text generation, you have to consider the result of these rules and expansions.
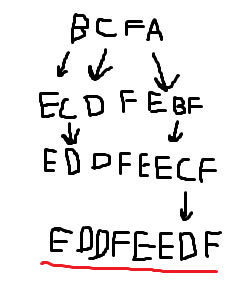
So now we’re only missing one last thing. The axiom. This is our baseline statement which we’ll apply our production rules on to form a final statement.
We'll make this our axiom: BCFA We'll look at each individual character and replace it with its production rule: B --> EC, C --> D, F remains, A --> EBF Then we bring those back together: ECDFEBF And we reapply our production rules: E remains, C --> D, D remains, F remains, E remains, B --> EC, F remains Bring it together: EDDFEECF One final application of our production rules: E remains, D remains, D remains, F remains, E remains, E remains, C --> D, F remains And we get our final result: EDDFEEDF
Here’s a bit more detailed visualization:
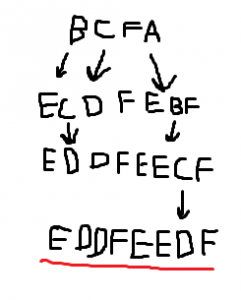
Gotta love MS Paint, right?
Context-Free Grammar for Text Generation
So now that we understand context-free grammars, let’s see how we can apply it to generate text. It’s helpful to start with an example sentence, so we’ll keep things simple.
Let’s start with this sentence: The dog barks.
Now we want to identify the major characteristics of the sentence we want to break down into production rules. For instance, we can make a non-terminal “noun” character which expands into a “dog” character. We can also make a non-terminal “verb” character which expands into a “barks” character. I’ll put this into a visual similar to last time now:
"noun" --> "dog" "verb" --> "barks"
Next, we want to rewrite our original sentence to form our axiom: The “noun” “verb”.
We then expand our terms using production rules: The remains, "noun" --> "dog", "verb" --> "barks" And we bring it together for our sentence: The dog barks.
So far, we’ve only dealt with production rules involving single expansions (e.g., A –> EBF, “noun” –> “dog”), but the true power of context-free grammars appears when we have multiple expansions per production rule. For example, we could set up the “noun” rule to have “cat”, “bird”, and “lizard” in addition to “dog”. That might look something like this: “noun” –> “dog”, “cat”, “bird”, “lizard”. Each of these expansions has an equal chance of being included in our final statement. Therefore, if we wanted a particular statement to be selected more frequently than others, we simply include it multiple times in the list of expansions.
By making the previous adjustment in our “noun” rule, we end up with different resulting statements:
The dog barks The cat barks The bird barks The lizard barks
We can also make more “verb” expansions to better reflect our new noun options. And we can do this to form more and more complex sentences. Rules can expand into other rules, or even into themselves. The sky is the limit as we better grasp and implement these concepts. That being said, we are making Twitter bots here, and there’s only so much complexity we need. If you want to get heavy into nested rules and recursion in a context-free grammar, more power to you, but we won’t be delving too deeply beyond small word replacements.
Now that we have an understanding of context-free grammar and a basic understanding of how to implement it for text generation, let’s look at how Tracery works for these methods.
At long last…Tracery
Tracery grammar objects are implemented in the form of JSON style objects. JSON is a data-interchange format that allows for the construction of objects and their information. They can be very particular though, so you have to really pay attention to what you type.
All JSON objects start with an opening curly bracket ( { ) and end with a closing curly bracket ( } ). So, an empty Tracery object would look like this:
{
}
Now, we want to occupy this space with our production rules. Tracery, by default, searches for an “origin” rule to serve as the axiom from which we’ll form our final sentence. So, all Tracery objects will have at least this:
{
"origin" :
}
Here, the colon ( : ) serves a similar role as the arrows I used earlier ( –> ) in that it marks what the expansions of our rules are. You have to surround the left side of the colon with quotation marks on each side ( ” ). Now, let’s make this look more like our dog barks example:
{
"origin" : [
"The #noun# #verb#"
],
"noun" : [
"dog"
],
"verb" : [
"barks"
]
}
I’ve added a lot of elements here, so let’s go through them one by one. Anything to the right of a colon is an expansion. These are done in arrays of strings, which are surrounded by straight brackets ( [ ] ) at the beginning and end of the set of expansion strings you want per rule. Each expansion is surrounded by quotation marks. If you have multiple expansions inside your array, you need to separate them with a comma ( , ) between each string, following the quotation marks. It’s important to not have a comma at the end of your array or the program won’t run correctly. You also need to separate each rule by including a comma after the closing straight bracket ( ] ), again avoiding a comma after the last rule and set of expansions. If you want to include a production rule as part of an expansion, you flag it on each side with a pound sign ( # ). Now, the line breaks and tab formatting I’ve done is fairly standard for JSON style objects. They don’t impact the text generation or anything, but they keep everything looking clean and organized. Let’s make a bit bigger Tracery object to show how arrays work.
{
"origin" : [
"The #noun# #verb#",
"The #verb# #noun#"
],
"noun" : [
"dog",
"cat",
"bird",
"lizard"
],
"verb" : [
"barks",
"meows",
"chirps",
"makes lizard sounds"
]
}
Here you can see how each list inside of an array is structured, with a comma following each element in the array. I’ve also created an array inside of the ‘origin’ rule, which will produce different sets of text. Remember, all elements in these arrays have equal odds for being selected as an expansion, so if you want a specific expansion to occur more frequently, just list it more than once.
That covers it for the basics of working with Tracery. Don’t forget you can include rules inside other rules to perform expansions. That’s how the ‘origin’ rule works, but the same principle can be applied to any rule in the grammar object. Now I want to talk about some more advanced things you can do with Tracery.
Cool Things Tracery Can Do
You may find times where you need a word to be capitalized sometimes at the start of a sentence, but not other times. Tracery has a dot operator that allows you to capitalize expansions as necessary. For example:
{
"origin" : [
"#animal.capitalize# are so cool! And #animal# are cool too!"
],
"animal" : [
"cats",
"dogs",
"birds",
"lizards"
]
}
The generated form of this text would look something like this:
Birds are so cool! And cats are cool too! Dogs are so cool! And dogs are cool too! Lizads are so cool! And birds are cool too!
Here you can see some failings of the Tracery program as it stands. Multiple inclusions of a rule result in different expansions of that rule, which isn’t always what we might want. Thankfully Tracery does have a way of resolving this using some minor flagging. Let me show you:
{
"origin" : [
"#[animal:animal_list]sentence#"
],
"sentence" : [
"#animal# are cool! I love #animal#"
],
"animal_list" : [
"cats",
"dogs",
"birds",
"lizards"
]
}
So you’ll notice that I included a new flag inside of the ‘sentence’ rule call for the origin rule. Inside of the pound signs before the naming the particular expansion, I created a new rule which applies only to the ‘sentence’ rule. Now, the ‘animal’ rule only expands into the ‘animal_list’ rule once, then applies it to every call of the ‘animal’ rule in ‘sentence’. The result is having the same expansion in every call of the ‘ animal’ rule:
Cats are cool! I love cats Dogs are cool! I love dogs Birds are cool! I love birds Lizards are cool! I love lizards
Moving back to Tracery’s dot operators, there are other operators that work in a similar fashion to the capitalization but do other augmentations to your expansions. For example, .s will make the expansion plural, .ed will put the expansion into past tense (be careful with this, though, as Tracery isn’t the best at handling past tense that isn’t ‘-ed’), .capitalizeAll will make every letter in the expansion capitalized, and .a will and ‘a’ or ‘an’ before the expansion. You can use as many of these in conjunction as you want, just keep including the dot. I’ll show some example formatting:
#example.s# #example.ed# #example.capitalizeAll# #example.a# #example.ed.capitalizeAll#
Whenever you combine dot operators, they simply add onto each other, implementing each augmentation to the expansion.
Other Resources
That covers what I know of how to use Tracery. I want to include some other tutorials you can use to study and better understand how tracery works, in case anything here was unclear or you just need more examples. I’ll also show you where you can use your Tracery knowledge to make a real-life Twitter bot.
The Crystal Code Palace has a Tracery tutorial that I found very helpful in learning the ins and outs of Tracery. It also features interactive code text boxes so you can practice using each element as you go through the tutorial. You can find it here: Crystal Code Palace Tutorial
Another great tutorial was made by Allison Parrish. It’s very simplistic and straightforward and does a good job of building Tracery from the ground up. You can find it here: Allison Parrish’s Tracery Tutorial
Now, if you want to toy around in a general text editor working in Tracery, I recommend this one from brightspiral.com. You can use the traditional JSON format, or you can use their editor to create symbols and expansions one by one. You can find it here: Tracery Visual Editor
GalaxyKate, the creator of Tracery, also has a visual editor for Tracery. I don’t find it as appealing as the other listed editor, but you can use whichever you prefer. You can find it here: GalaxyKate Tracery Visual Editor
So now that you know how to write in Tracery, it’s time to make a Twitter bot! Cheap Bots Done Quick is the choice of many bot creators, most notably Nora Reed. All you do is log in using the Twitter account you want to use as a bot, paste in the Tracery code in JSON format, and choose how frequently you want it to post. You can find it here: Cheap Bots Done Quick
Speaking of Nora Reed, she has her own list of bot making resources that are helpful. You can find it here: Nora Reed Bot-Making Resources
Wrapping things up…
I think this post has gone on long enough. Hopefully, you’ve seen how Tracery can be used to generate sentences, which can then be posted to Twitter to become a Twitter bot. Let us know what kind of bots you’re making by tagging our Twitter handle: @DH_UNT. Happy botting everyone!
Leave a Reply