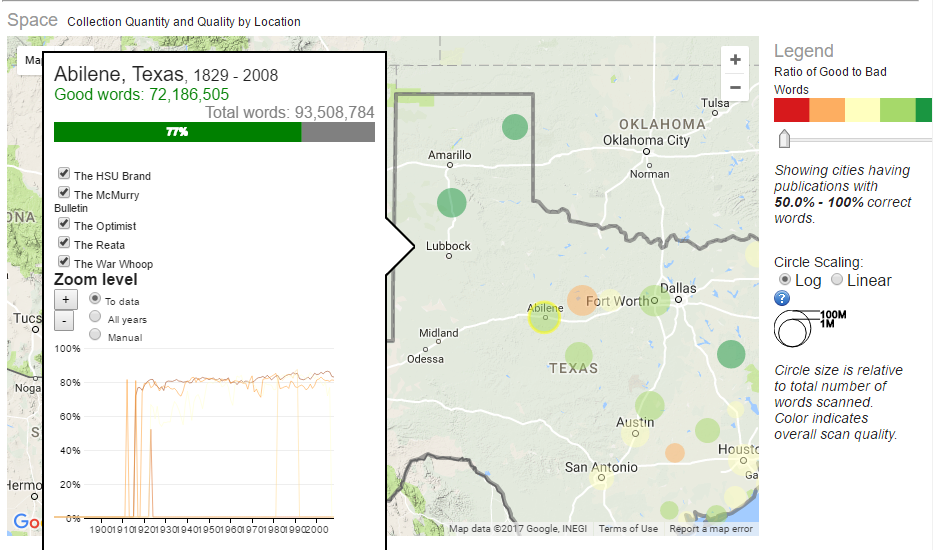
Visualization of the quantity and quality of scanned historical newspapers.
- GNU Aspell is an Open Source spell checker that was used to correct recurring errors introduced by the OCR process.
- MALLET was used for topic modeling, which uses statistical methods to uncover connections between collections of words (“topics”) that appear in a given text.
- Stanford NER is a program that attempts to identify and classify various elements in a text (i.e., nouns such as people or location).
- GitHub – The source code was uploaded here for downloading and re-use.
Get Started
Resources:


Leave a Reply