



via https://medium.com/@startuphackers/building-a-deep-learning-neural-network-startup-7032932e09c
It seems that artificial intelligence enters more and more into the mainstream every day. Discussions around neural networks and how to best optimize and implement them happen everywhere, especially as the information on how to create them becomes more and more accessible to the public. However, one major issue I do not see being discussed in the mainstream is that of ensuring that the kind of information we feed these networks is sufficient to train them in a way that creates effective results. Here I want to discuss some of the foundational elements of neural networks and how they’re trained, as well as highlight some examples in which I feel there was a poor use of given data used to train or implement certain neural networks as a means of exemplifying the effects caused by the lack of this discussion.
What is AI? What are Neural Networks?
The term artificial intelligence generally refers to any intelligence not formed by natural means. In the last few years, though, it has come to specifically refer to seemingly intelligent computer programs that mimic human behavior in some form or another. This could be recognizing faces in photographs, composing music, or even generating news blurbs.
Most modern artificial intelligence (AI) operates using an algorithm style called neural networks. This method matches some patterns recognized in human learning by behaving similarly to human neurons. In a neural network, ‘neurons’ behave as a way of storing some small amount of data that, when calculated together, result in some action on part of the AI. Connecting these ‘neurons’ are ‘axons’. These are weighted connections that affect the way the network interprets the information it’s been given. They give the AI a sense of what may or may not be more correct in determining its output.
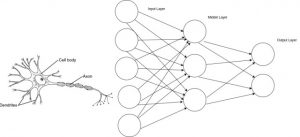
via https://blog.knoldus.com/2017/06/08/first-interaction-artificial-neural-network/
Generally, there are 3 layers of neurons within a neural network: an input layer, a hidden layer, and an output layer. The input layer acts as a means of taking in information to feed into the hidden layer. It could be comprised of thousands of inputs, or just two; it all depends on how much data you want your network to take in and may require tweaking over time. The hidden layer is equally variable in its number of neurons. In fact, it may even contain more than just one layer. The reason it’s referred to as the ‘hidden’ layer is that most of the information processing happens here, and its method for acting is typically unknown to the programmer. The hidden layer feeds into the output layer. This is where the network makes some guess as to what it thinks is the appropriate answer to the task it’s been assigned.
Now, these networks aren’t created very directly. In fact, many of the starting values and outcomes tend to be quite random. This is why we have to ‘train’ networks to be efficient at their tasks. We do this by feeding it data of which we know what the expected outcome should be, comparing its results to the desired outcome, then having the program readjust the weights in the ‘axons’ to more accurately predict the correct outcome. For example, if I wanted a network to determine whether I should turn left or right along a path, I would provide it with examples where I already know which direction I should turn. Then I can analyze the results and see the amount of error in the networks guesses, and alter the system accordingly to minimize that error. If I do this enough times, the network will be able to predict the appropriate direction to turn almost 100% of the time.
I’ve kept this explanation of neural networks fairly simple, but if you want an extremely detailed explanation that delves into a lot of the maths involved in this process, here’s a playlist that goes more in depth on the subject:
I want to take a moment to note that the specific type of neural network I’ve just described is called a feedforward neural networks. It is called this because all the data in the network moves in one direction with no loops: input, hidden, output. There are other types of neural networks that use loops in their data processing. I also want to note that there are other methods for training and developing networks, such as the evolutionary model. Networks formed from the evolutionary model are initially created randomly within given parameters, then tested on some measure of their capacity to complete the given task. The best networks from each ‘generation’ are then kept and ‘bred’, while the others are deleted, creating another ‘generation’. This continues many times until an efficiently capable network is produced.
MarI/O and Information Loss
So now that we’ve established how neural networks function, let’s look at one in action. MarI/O is an AI written by YouTuber SethBling and is designed to complete a level in his Mario emulator. The network is trained using an evolutionary method, using blocks on the screen as inputs. In this video, SethBling goes into detail on how the whole thing works:
Essentially, data points sensing blocks on the screen correspond to the pressing of buttons, which then cause Mario to move and act. But SethBling’s AI misses out on some major elements in Mario: defeating monsters, collecting coins, and any other various score increasing features. The point isn’t simply to complete the level, but rather to clear it of enemies and gather all available loot. And this is where MarI/O begins to break down fundamentally.
To begin, there are only two potential inputs: blocks detected as stable (the ground) and blocks that are moving. Now, the ground is definitely a good choice for an input, but lumping all moving objects into one category for detection is far too reductive. For instance, some moving objects (like mushrooms) we would want to move towards, but others (like enemies and projectiles) we would want to jump on or move away from. Not to mention, lumping all enemies into the same category removes any potential pattern recognition for specific enemy types.
The other shortcoming of MarI/O is its limited input layer. Rather than making detections of all blocks on the screen, only some are selected at random until trained to have more. I feel that this leaves out a vast amount of data to be collected and limits the overall functionality of the AI.
And this is the type of discussion that seems to be lacking from the public discussion around AI development: the effective input of data to yield substantive results. Neural networks are only as effective as the data they are given to train from, so we have to ensure that the amount of data they are given is significant enough to yield appropriate results. Sometimes this can be easy to see, as in the case with MarI/O, but other times questioning the kind of data a network receives and how to effectively improve it are much more complicated, as we will soon see.
So… Ya Like Jazz?
Carykh tinkers with evolutionary neural networks. In this video, he wanted to create an AI that would generate jazz music for him. He used several different pre-made neural networks and trained them each to try to generate music. You can see his explanations in more detail in the video:
As you can see, two of the networks were trained using images as a translation for midi files. And one of those networks won as the best at recreating jazz. But is this really an ideal way to train AI to make music?
While carykh does point out the limitations of this format, he simply dismisses them as inherent to the situation, rather than seeking out either better networks to experiment with or improving the input data. Is it any wonder that an AI designed to detect shapes and images failed to recreate music through carykh’s bodged musical translation?
I feel that this is the road that most AI is headed when the mainstream fails to see the importance of appropriate data. In the examples I’ve given, it’s fairly obvious that there’s missing or inaccurate data being fed to the networks. And in the case of carykh’s jazz AI, it can even become cloudy as to what the appropriate data for the expression of music would even be. Looking more broadly, it could even be the case that someone might be using inaccurate data and not realize it, resulting in countless hours of frustration at poor results and tweaking of processes, when data is to blame the whole time.
And that’s really what I want to bring into the discussion here. As we develop these AIs, we the public need to better question the practicality of the data in use.
Wrapping this up
I hope you enjoyed learning about neural networks and beginning to question some of the data that we feed them. Let us know if you’ve been involved in any AI or neural network projects and what problems you may have faced in your development process. You can tweet us @DH_UNT or leave a comment down below. And I, for one, welcome our new neural network overlords.
Leave a Reply